Exploiter les données en vie réelle : focus sur les algorithmes
L’apprentissage supervisé
Définition
L’apprentissage supervisé consiste à développer des algorithmes capables de concevoir un modèle de prédiction à partir de données annotées. Ce modèle de prédiction se fonde sur l’apprentissage et la maîtrise d’une fonction de mapping entre des variables d’entrées (X) et d’une variable à prédire (Y).
L’apprentissage est initié à partir d’un set de données d’entraînement réunissant des données annotées (ex. malade, pas malade). A partir de ce set de données, l’algorithme apprend à ajuster ses paramètres pour maximiser ses performances de prédiction (sa maîtrise de la fonction de mapping).
L’algorithme effectue ainsi des prédictions itératives sur les données d’apprentissage et est corrigé par l’enseignant. L’apprentissage s’arrête lorsque l’algorithme atteint un niveau de performance jugé acceptable.
L’apprentissage supervisé est le modèle d’apprentissage automatique le plus utilisé aujourd’hui et celui qui produit les meilleurs résultats. Il nécessite toutefois de mobiliser de nombreuses ressources afin d’étiqueter les données avec les résultats attendus correspondants, tâche aussi complexe et coûteuse qu’essentielle dans ce processus.
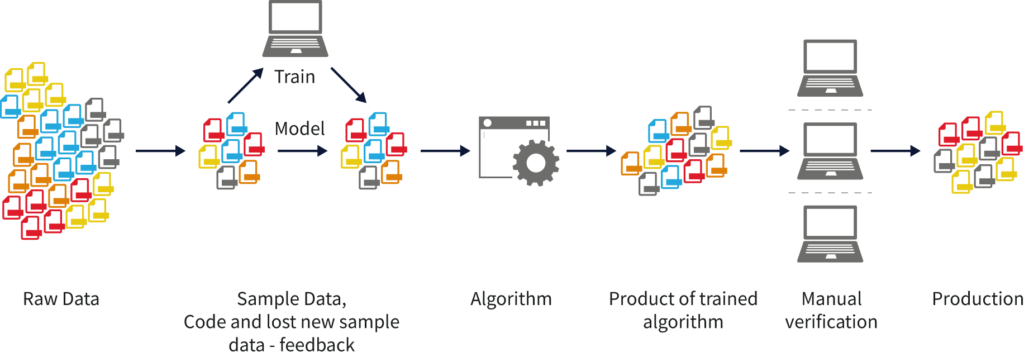
Types d’algorithmes
Les modèles d’apprentissage supervisé se structurent notamment autour de deux familles d’algorithmes: les algorithmes de régression et de classification.
Un problème de régression se pose lorsque la variable à prédire de sortie (Y) est une variable continue (variable pouvant prendre une infinité de valeurs – ex. toute valeur entre 1 et 2).
Les algorithmes de régression peuvent prendre plusieurs formes en fonction du modèle que l’on souhaite construire.
La régression linéaire est le modèle le plus simple : il consiste à trouver la meilleure droite qui s’approche le plus des données d’apprentissage.
Les données n’ayant pas forcément une relation linéaire entre elles, et plusieurs variables pouvant être nécessaires pour effectuer une prédiction réaliste, des modèles de régression polynomiale et multivariées permettent de calculer des fonctions de mapping complexes.
Usages possibles
- Prédire l’évolution d’une grandeur (température, pression sanguine…)
- Prédire la diffusion d’une épidémie
- Simple Linear Regression
- Multiple Linear Regression
- Polynomial Regression
- Support Vector Regression
- Bayesian Regression
- Decision Tree Regression
- Random Forest Regression
- Cox model
- Longitudinal joint model
- Survival random forest
On parle d’un problème de classification quand la variable à prédire est une variable discrète (variable ne pouvant prendre qu’un nombre fini de valeurs – ex. 1 ou 2, malade ou pas malade). La classification supervisée est la catégorisation algorithmique d’objets. En se basant sur des modèles statistiques, l’algorithme développé doit prédire à quelle classe appartient la donnée. Cette classification peut compter deux dimensions (binaires) ou plus (multi-classes).
Usages possibles
- Identifier des cellules cancéreuses
- Orienter vers une recommandation de traitement
- Détecter une chute (personne debout ou non)
- Choisir un régime alimentaire
Exemples de modèles statistiques/mathématiques mobilisés
- Logistic Regression/Classification
- K-Nearest Neighbours
- Support Vector Machines
- Kernel Support Vector Machines
- Naive Bayes Decision
- Tree Classification
- Random Forest Classification
Les différents modèles d’apprentissage
Plusieurs modèles d’apprentissage automatique peuvent être envisagés. Chacun de ces modèles a ses spécificités et permet de répondre à des objectifs précis. Ces modèles peuvent mettre en œuvre un algorithme, ou en combiner plusieurs (ensemble learning). Les principaux modèles sont présentés dans la section suivante :



