



Sous l’égide du![]()
A l’inverse de l’apprentissage supervisé qui tente de trouver un modèle depuis des données étiquetées, l’apprentissage automatique non-supervisé est utilisé lorsque les informations fournies pour former le modèle ne sont ni classées ni étiquetées.
L’objectif de l’apprentissage non supervisé n’est pas de déterminer une prédiction mais de modéliser la structure ou la distribution sous-jacente dans les données qui sont étudiées afin d’en apprendre davantage sur celles-ci.
On l’appelle apprentissage non-supervisé car, contrairement à l’apprentissage supervisé, il n’y a pas de réponse correcte ni d’enseignant.
L’algorithme apprend à partir de données brutes, élabore sa propre classification et présente les structures de données qu’il juge intéressantes. La classification qu’il propose est libre d’évoluer lorsque des éléments nouveaux lui sont présentés.
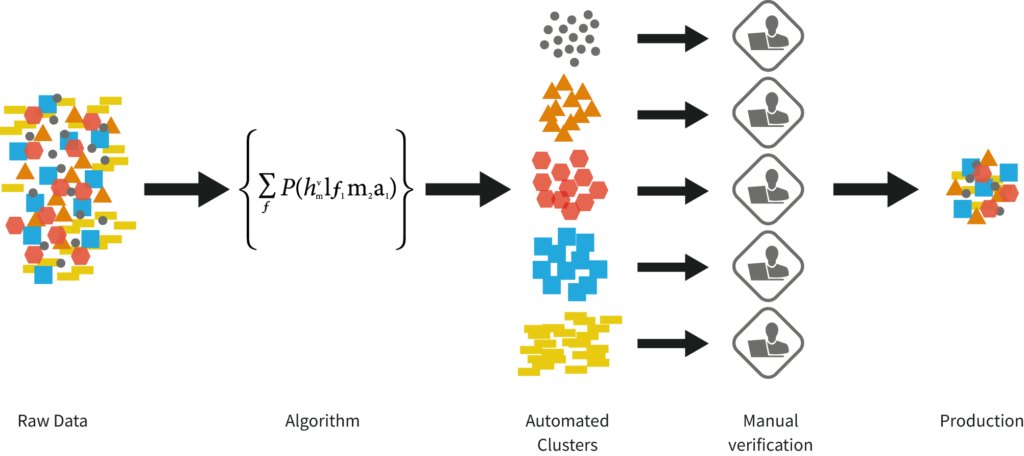
L’algorithme s’appuie notamment sur des fonctions de similarité, de distance entre les cas pour les regrouper en classes. La pertinence des classes obtenues doit être revue et validée par des experts avant de décider si l’algorithme peut être déployé en pratique.
L’apprentissage non supervisé comprend deux principales catégories d’algorithmes: les algorithmes de clustering et d’association.
Le clustering est un processus qui permet de rassembler des données similaires. En appliquant des techniques d’apprentissage, l’algorithme de clustering va trouver certaines similarités entre les données permettant de classer celle-ci. Ce type d’analyse permet de mettre en évidence des groupes aux profils différents. Cela permet donc de simplifier l’analyse des données en faisant ressortir les points communs et les différences et en réduisant ainsi le nombre de variables des données.
Quelques exemples
Exemples de modèles statistiques/mathématiques mobilisés
La recherche des règles d’association est une méthode dont le but est de découvrir des relations ayant un intérêt entre deux ou plusieurs variables stockées dans de très importantes bases de données. Les algorithmes d’association sont particulièrement adaptées pour explorer des bases de données volumineuses ou complexes. Par exemple, ils peuvent identifier la probabilité de co-occurrence d’éléments dans une collection de données.
Quelques exemples
Plusieurs modèles d’apprentissage automatique peuvent être envisagés. Chacun de ces modèles a ses spécificités et permet de répondre à des objectifs précis. Ces modèles peuvent mettre en œuvre un algorithme, ou en combiner plusieurs (ensemble learning). Les principaux modèles sont présentés dans la section suivante :
Les cookies nécessaires sont absolument indispensables au bon fonctionnement du site. Cette catégorie comprend uniquement les cookies qui assurent les fonctionnalités de base et les fonctionnalités de sécurité du site Web. Ces cookies ne stockent aucune information personnelle.
Tous les cookies qui peuvent ne pas être particulièrement nécessaires au fonctionnement du site Web et qui sont utilisés spécifiquement pour collecter des données personnelles des utilisateurs via des analyses, des publicités et d’autres contenus intégrés sont appelés cookies non nécessaires. Il est obligatoire d’obtenir le consentement de l’utilisateur avant d’exécuter ces cookies sur votre site Web.
Les cookies analytiques sont utilisés pour comprendre comment les visiteurs interagissent avec le site Web. Ces cookies aident à fournir des informations sur les mesures du nombre de visiteurs, du taux de rebond, de la source du trafic, etc.