



Sous l’égide du![]()
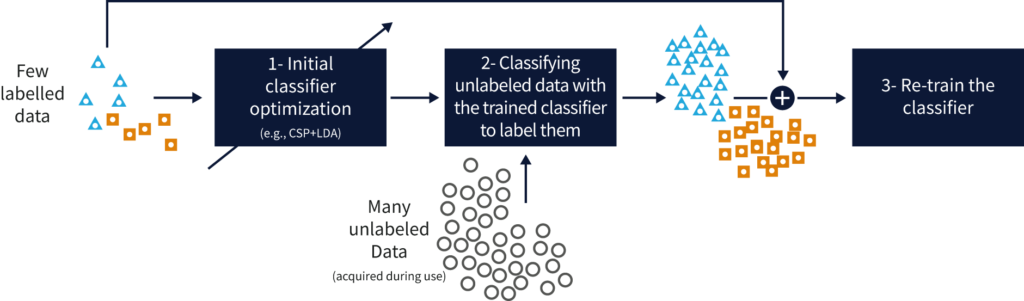
Comme son nom l’indique, l’apprentissage semi-supervisé se situe entre l’apprentissage supervisé et l’apprentissage non-supervisé. Cette méthode est employée lorsque seule une partie des données d’entrée est étiquetée.
Les algorithmes sont développés pour apprendre des données étiquetées et des données non-étiquetées afin de produire un modèle d’analyse mixte.
Cet apprentissage peut être mené en étape successives (l’algorithme apprend d’abord sur les données étiquetées puis approfondit son apprentissage sur les données brutes pour affiner le modèle) ou parallèle (l’algorithme réalise deux apprentissages: un sur les données étiquetées, un sur les données brutes, avant de converger sur une méthode unique).
Le principal intérêt de ce modèle est qu’il ne nécessite que quelques données étiquetées, réduisant de fait la charge de préparation des données qui peut s’avérer longue et coûteuse lorsque les sources de données à exploiter sont volumineuses et complexes.
Plusieurs modèles d’apprentissage automatique peuvent être envisagés. Chacun de ces modèles a ses spécificités et permet de répondre à des objectifs précis. Ces modèles peuvent mettre en œuvre un algorithme, ou en combiner plusieurs (ensemble learning). Les principaux modèles sont présentés dans la section suivante :
Les cookies nécessaires sont absolument indispensables au bon fonctionnement du site. Cette catégorie comprend uniquement les cookies qui assurent les fonctionnalités de base et les fonctionnalités de sécurité du site Web. Ces cookies ne stockent aucune information personnelle.
Tous les cookies qui peuvent ne pas être particulièrement nécessaires au fonctionnement du site Web et qui sont utilisés spécifiquement pour collecter des données personnelles des utilisateurs via des analyses, des publicités et d’autres contenus intégrés sont appelés cookies non nécessaires. Il est obligatoire d’obtenir le consentement de l’utilisateur avant d’exécuter ces cookies sur votre site Web.
Les cookies analytiques sont utilisés pour comprendre comment les visiteurs interagissent avec le site Web. Ces cookies aident à fournir des informations sur les mesures du nombre de visiteurs, du taux de rebond, de la source du trafic, etc.